Why Better AI Coding Models Made Your Team's Shared State Worse
Your developers got faster. Your delivery did not. The reason is not the model. It is the layer of shared state nobody on your team agreed to own when you started running two AI coding tools at once.

Three tools, three context windows, and one question none of them can answer: what is the team actually working on right now.
Your individual developers got faster this year. Your team did not ship more stably. The explanation most leads reach for is that the model wrote code nobody reviewed properly. That explanation is wrong, or at least it is downstream of the real one: AI coding team shared state.
The DORA 2025 research names the mechanism without naming the cause. Its central finding is that "AI's primary role is as an amplifier, magnifying an organization's existing strengths and weaknesses." [1] Read that carefully. A better model multiplies whatever coordination you already have. If your team's shared state is clean, the model amplifies clean work. If a layer is unowned, the model amplifies the gap.
This post is about the layer most teams have left unowned. When you run two AI coding tools at once, you do not have one shared state problem. You have three. Most teams have accidentally solved two of them. The third is where the stability went.
The Multi-Tool Setup Is Already Your Setup
Start with the premise, because the rest of the argument depends on it. Running more than one AI coding tool is not an edge case anymore. It is the default.
According to BuildBetter.ai, citing the 2026 GitHub Octoverse and JetBrains State of Developer Ecosystem reports, 63% of engineering organizations now use two or more AI coding assistants concurrently. [2] Treat that as a practitioner figure rather than a primary statistic, because the underlying reports were not independently re-verified here. But the direction matches what teams actually do, and you can probably name your own stack without thinking hard.
Here is the shape it usually takes. A team adopts Cursor first, because the in-editor flow is the easiest on-ramp. A few months later someone adds Claude Code for the longer autonomous runs that the IDE does not handle well. Later still, Codex gets wired into the CI pipeline. Three tools. Three context windows. Each one generating real output every day.
Nobody made a shared state decision along the way. Nobody needed to. Each tool worked on its own, the demos were good, and the developers using them were faster than they were last year. The decision got skipped because the cost of skipping it does not show up until the review queue starts growing and nobody can say why.

If your team is still deciding which tools to adopt rather than how to coordinate the ones you have, the control surface selection framework covers that earlier decision: where the human's steering point should live for each tool architecture. This post starts one step later, after the tools are in the building.
Three Layers of AI Coding Team Shared State (You Have Probably Solved Two)
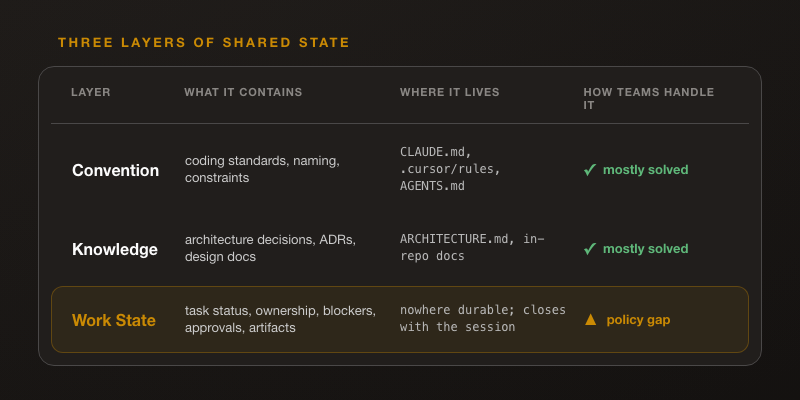
Not all shared state is the same. Pull it apart and there are three layers, and they behave differently enough that one solution cannot cover all three.
The closest published framework is BuildBetter.ai's context architecture, which proposes a canonical /context directory that generates each tool's config: CLAUDE.md, .cursor/rules, AGENTS.md, and so on. [2] It is a good idea, and it solves a real problem. It also stops at the first layer. Naming what the leading practitioner resource reaches and what it misses is the cleanest way to see the gap.
Layer 1, the convention layer. This is your coding standards, naming rules, architectural constraints, the do-not-touch list. It lives in CLAUDE.md, .cursor/rules, AGENTS.md. It is static, it sits in files, and it is versioned in git. The Stack Overflow blog confirms the direction the whole industry is moving here: standards files should live in version control alongside agent configuration, and agents need deterministic guidelines rather than the conventions a human absorbs by osmosis. [4] If your team has invested any deliberate effort in AI practice, Layer 1 is mostly handled. The sync tools exist. The files are in the repo.
Layer 2, the knowledge layer. ARCHITECTURE.md, the ADRs, the in-repo design notes that explain why the system is shaped the way it is. This one is also git-native, and most teams maintain it as a byproduct of normal engineering hygiene. No special tooling. If you write decent design docs, Layer 2 takes care of itself.
Layer 3, the work state layer. What task is in progress right now. Who owns it. What is blocked, and on what. What got approved, and by whom. What artifacts came out of which session. This layer is dynamic. It changes minute to minute. It crosses session boundaries and person boundaries, and crossing those boundaries is the entire point of it. Almost no team has a written policy for who owns it.
The difference that matters: Layer 3 cannot live in a file. A file records a decision once and holds it still. Work state is not still. It moves while you read this sentence.
You have the taxonomy now. The next question is why the file-based approach that handled Layers 1 and 2 cannot be stretched to cover Layer 3.
Why File Sync Cannot Reach Work State
The limitation sits in the data model underneath the sync mechanism.
A convention file records a stable decision. "Use tabs. Prefer composition over inheritance. Do not touch the billing module without review." Those facts are true on Monday and still true on Friday. Copy the file, the decision travels with it, done. That is what file sync is good at, and it is genuinely good at it.
Work state records a live decision, and live decisions have a timestamp attached that matters. A task moved from in-review to blocked at 11:43 this morning because a dependency shifted, and the agent's context was never told. A sync tool can copy a file. It cannot record a transition that happened after the file was written. The Augment Code operating model puts the structural version of this plainly: organizational memory must become infrastructure rather than something improvised per team, because multi-agent systems generate synchronization overhead through lossy communication between sessions. [5] Lossy is the key word. Every session boundary is a place where state can drop.
Here is the concrete version, the one I see most often. Developer A runs a Claude Code session in Singapore in the evening. It produces a work item: a PR stub, a status change, a handoff note flagging that the migration is blocked on a schema review. Developer B opens Cursor the next morning in another time zone to pick it up. Where is the record of that handoff?
It is not in CLAUDE.md. CLAUDE.md records conventions, and a blocked migration is not a convention. It is not in ARCHITECTURE.md. That records system design, and a one-night blocker is not a design decision. When Developer A's session ended, the work state for that handoff lived in the context window, and the context window closed when the session did. Developer B opens to a blank slate and a PR stub with no story attached. The blocker gets rediscovered, not retrieved. That rediscovery is the cost, paid again every handoff.
The test for whether Layer 3 is owned is a single question: what task is in progress right now, and who approved the last commit? A carefully maintained CLAUDE.md is silent on both. That silence is Layer 3, and the silence is what the model amplifies.
The DORA Paradox Is a Layer 3 Problem
Now the stability finding lands, because there is a mechanism under it.
DORA's amplifier principle says AI magnifies existing strengths and weaknesses. [1] Apply it to a team with an unowned Layer 3. The model generates code faster. The code is fine, even good. But it flows into an environment where nobody has a durable answer to what is in progress and who owns it. So the faster generation does not amplify delivery throughput. It amplifies the review backlog, because review is now the place where all the untracked work piles up waiting for someone to reconcile it.
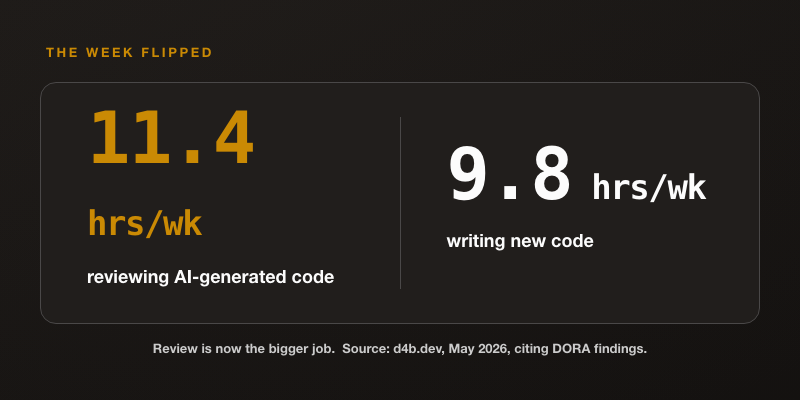
The numbers show the reversal. According to d4b.dev, citing DORA findings, developers now spend 11.4 hours per week reviewing AI-generated code against 9.8 hours per week writing new code. [3] Review has become the bigger job. That reversal is a coordination symptom, not a model-quality one. A better model would write more code faster and push the imbalance further. Work generates faster than anyone tracks who owns it, so it stacks up at the one human checkpoint that cannot be parallelized.
Two objections are worth meeting head on.
The first: a better model should fix the stability problem. It will not, and DORA's framing is why. The amplifier finding is organizational, not model-driven. A stronger model producing more correct code faster into a fragmented work-state environment produces a larger review backlog with more ambiguous ownership, not a smaller one. The binding constraint is not code quality. It is coordination capacity, and you cannot buy more of that with a model upgrade.
The second: maybe the answer is to run one tool and avoid the whole problem. Pragmatically, most teams are already past that exit. With 63% running two or more, the state-governance problem exists whether anyone named it or not. [2] Cutting back to one tool is a real option for a small team that has not committed yet. It is not available to the team that already has Cursor, Claude Code, and Codex in production. For them the move is not fewer tools. It is governing state across the ones they have.
The norms-and-culture dimension of the same decline, how teams agree to review AI-generated work, is a companion problem. The team norms conflict post covers that angle. This post stays on the architectural layer, and the architectural fix is a decision with three specific questions attached.
The Policy Decision That Comes Before the Tool
The fix is a decision, and you can probably make it with infrastructure you already have once you have named it.
Governance-tier thinking already exists in this space. Augment Code describes three tiers for agent actions: Tier A is human-only, Tier B is agent-assisted with human approval, Tier C is fully autonomous within policy bounds. [5] That is the same concept this post is pushing, applied one level down: from governing what an agent is allowed to do, to governing where the record of what it did lives. The Layer 3 policy is governance-tier thinking for state ownership.
Three questions decide it. Ask them in an actual team meeting, not rhetorically.
One. Which system in our stack is the authoritative record of what is in progress, what is blocked, and what has been approved? If the honest answer is "Slack threads, a few side chats, and whatever the last developer remembers," then Layer 3 is unowned. Name the system, or admit there isn't one.
Two. Can every AI coding tool in our stack query that system directly, or does a human have to carry state between sessions by hand? If a person is the integration layer, the work state drops every time that person is asleep, in a meeting, or in another time zone. A cross-border team feels this first, because the handoff window is built into the calendar.
Three. When any session ends, where does its work state live? If the answer is "in the context window," the answer is "nowhere," because the context window closes with the session. Work state needs a home that outlives the session that created it.
The teams that have answered all three are not running fewer tools than you. They are running the same tools with a policy layer underneath. Their agents can ask what the current status of a task is and get an answer that did not depend on a session staying open or a person staying awake.
This is the gap Agiflow was built to close: a queryable work-state record that sits outside every tool, so Cursor, Claude Code, and Codex all read and write the same answer to "what are we working on right now." See how Agiflow tracks work state across tools and sessions. It is one concrete instance of the Layer 3 home the three questions point at, not the only possible one.
For teams that have settled the policy layer and are ready to architect the technical handoff contracts between agents, the role-separation post covers that next layer down.
The Variable You Can Actually Move
The DORA stability paradox looks like a model problem, because model output is the most visible thing in the stack. That is the part teams benchmark, screenshot, and argue about on a Friday. So that is where teams point when delivery stalls.
The teams resolving it have not switched to a different model. They named which system owns Layer 3, and they made sure every tool in the stack can read and write to it. Your developers are already fast. The question is whether your AI coding team's shared state has a home outside the tools, or whether the session takes it when it closes.
See how Agiflow tracks work state across tools and sessions.
References
More to read
Why Your Team's AI Coding Tool Breaks at Scale (And It's Not the Model)
Every team benchmarks AI coding tool quality. Almost nobody asks where the control surface lives or who owns shared state when the session ends. That second question is the one that breaks teams at scale.
10 min readSpec-Driven Development Tools: Where AI Project Memory Lives Is the Only Decision That Matters
The spec-driven development tool landscape grew from 6 to 13 tools in a single community repo, not because the field is converging, but because three communities are building on incompatible assumptions about where AI project memory should live.
11 min read5 Dimensions That Separate a Real MCP Integration From a Read-Only Wrapper
Nearly every PM platform ships an MCP server now. Here is a 5-dimension framework for telling whether a given integration will change how your team works or just add a checkbox.
10 min readPut this project board inside ChatGPT
Open Agiflow in ChatGPT to plan campaigns, create tasks, and check what needs attention. Create a free Agiflow account when you are ready to keep the board for your team.