Multi-Agent Orchestration with Claude and Codex: Role Separation, Handoff Contracts, and Verification Gates
Architect multi-agent code systems that stay coherent. Learn role separation patterns, handoff contracts, and verification gates to prevent coordination failures.

Across 1,600 execution traces spanning seven multi-agent frameworks, researchers at the MAST project found that 36.94% of all system failures were coordination failures — not model failures [24]. The agents weren't hallucinating because they were dumb. They were failing because no one defined the boundaries, contracts, and verification checkpoints between them.
Claude Desktop and Codex CLI are the two most commonly paired runtimes for code-generation orchestration in 2026. Their capabilities overlap enough that teams often use them interchangeably — and that interchangeability is exactly where coordination failures start. One agent plans. The other implements. Neither has a formal agreement about what state to pass, what scope is bounded, or what verification happens at the boundary. Three iterations later, the output has drifted from the original plan and nobody knows when it happened.
The teams that keep multi-agent code systems coherent don't use better models — they use disciplined architecture: role separation by runtime capability, evidence-based handoff contracts, and verification gates that catch drift before it propagates.
This post covers six layers of that architecture: the runtime trade-off decision, role separation patterns, handoff contract design, context discipline, verification gates, and failure mode defenses. If you're building systems that balance cost and execution speed, see optimising agentic workflow cost and speed for complementary techniques.
The Coordination Problem — Why Multi-Agent Systems Break Before They Scale
The dominant failure mode in multi-agent code systems is not hallucination. It is not a context window limit. It is the absence of architecture.
The MAST taxonomy — built from 1,600+ execution traces across seven production frameworks — categorizes 36.94% of failures as coordination-related: failures that emerge at the boundary between agents, not inside any single agent's reasoning [24]. Supporting analysis from NimbleBrain and Redis independently confirm the pattern: when multi-agent systems fail, the most common root causes trace back to undefined responsibilities, missing state contracts, and lack of inter-agent verification [19] [23].
The Three Coordination Failure Patterns Most Common in Claude + Codex Setups
Drift occurs when output diverges from the original plan across iterations. The planner defines a bounded scope in iteration one. The executor, lacking a formal contract that prohibits scope expansion, adds adjacent functionality in iteration two. By iteration four, the system's behavior no longer matches the original intent — and neither agent flagged the deviation, because neither was tasked with detecting it.
Context loss occurs when the rationale from one agent doesn't survive the handoff to the next. This is especially acute in Claude + Codex setups: Claude Desktop accumulates planning context across a session — constraint decisions, dependency trade-offs, architectural reasoning. When that session hands off to Codex, only a portion of that rationale survives. The executor has the what but not the why, and fills the gap with inference that may be wrong [14].
Conflicting edits occur when two agents operate on the same file without a merge contract. In parallelized Codex setups where multiple instances handle different subtasks, the absence of an explicit scope lock means two executors can independently modify a shared module — each producing locally valid output that is globally incoherent [28].
All three failures share a common root: no one defined what each agent is responsible for, or what it can see. That starts with the runtime decision.
The Runtime Decision — When Claude Desktop Leads, When Codex Executes
The first architectural question in any Claude + Codex setup is not "how should they communicate?" It is "what is each one actually for?"
These runtimes are not interchangeable. They have meaningfully different strengths, context footprints, and operational modes — and the teams that build coherent multi-agent systems assign tasks accordingly [7] [8].
What Claude Desktop Does Well
Claude Desktop is a planning and coordination runtime. Its design assumptions favor:
- Long-context reasoning across multiple files and sessions. The plan sidebar persists intent; the file tree provides workspace awareness; MCP tool access means Claude Desktop can reach external systems, read context from task management tools, and surface cross-cutting dependencies [1] [5].
- Orchestration across subagents. Claude Desktop is the natural orchestrator for multi-agent setups — it can delegate to subagents, track their outputs, and revise the plan based on what comes back [1].
- Review and critique. Given a Codex output and the original acceptance criteria, Claude Desktop can evaluate whether the output matches intent, identify gaps, and generate targeted follow-up tasks.
Where Claude Desktop struggles: headless operation, programmatic integration, and parallel execution at scale. It is optimized for a human-in-the-loop session model, which makes it expensive to use for volume implementation work.
What Codex CLI Does Well
Codex CLI is an execution runtime. Its design assumptions favor:
- Headless, programmatic operation. Codex runs from the command line, integrates with CI/CD pipelines, and can be spawned as multiple parallel instances against isolated scopes [25] [26].
- Lightweight context per task. Codex is optimized for targeted, bounded implementation work — it doesn't carry session history between runs, which makes it cheap for high-volume, low-coordination tasks [8].
- Fast feedback loops. For atomic subtasks with clear acceptance criteria, Codex can implement, verify, and return output quickly without the overhead of a full planning session.
Where Codex struggles: tasks that require cross-cutting awareness, architectural judgment, or access to context that isn't in the immediate task spec. Hand it an ambiguous task and it will implement — confidently, and probably incorrectly.
The Runtime Decision Matrix

| Dimension | Claude Desktop | Codex CLI |
|---|---|---|
| Best for | Planning, coordination, review, cross-agent orchestration | Implementation, parallel execution, CI integration |
| Context model | Session-persistent; cross-file awareness; MCP tools | Task-isolated; per-invocation; no session state |
| Latency | Higher (interactive model) | Lower (headless, optimized for throughput) |
| Cost profile | Higher per token; justified for reasoning-heavy work | Lower per task; cost-efficient for bounded execution |
| Parallelism | Limited; single session model | High; multiple instances against isolated scopes |
| Failure mode | Over-coordinates; delays execution | Under-coordinates; scope creep or missing context |
Knowing which runtime leads tells you who orchestrates. The next question is harder: what exactly is each agent allowed to do?
Role Separation — Giving Each Agent a Jurisdiction
Runtime assignment tells you which system runs the work. Role separation tells you which agent makes which decisions. These are different problems, and conflating them is how you end up with a Codex instance that decides to refactor the auth layer because it looked wrong, or a Claude Desktop session that starts writing implementation code because the plan was vague.
The planner-executor architecture with disciplined role separation has been documented to reduce token costs by approximately 45% — not because less work is done, but because each agent operates within its competence and doesn't repeat work that belongs elsewhere [17]. For a detailed look at how structured task decomposition improves coordination, see work unit coordination patterns.
Pattern 1 — Planner-Executor
This is the foundational pattern for Claude + Codex orchestration.
Claude Desktop (Planner): Decomposes the overall task into atomic subtasks, resolves dependencies between them, and tracks progress across iterations. The planner holds the canonical plan and is the only agent authorized to revise it.
Codex (Executor): Implements atomic subtasks only. Does not expand scope, does not modify the plan, does not communicate with other Codex instances.
Boundary rule: The executor receives a task spec with explicit scope and acceptance criteria. It returns an output with artifact references. It does not modify the plan; the planner does not write implementation code.
Failure mode if violated: If the executor is allowed to expand scope, you get drift — the plan no longer reflects what's been built. If the planner writes implementation code, you lose the separation that keeps the system's reasoning clean [17] [18].
Production teams running 2–5 parallel Claude Code agents report that this boundary is the most important to enforce: once executors start interpreting the plan rather than following it, coordination cost rises faster than execution throughput [2].
Pattern 2 — Critic-Actor
The critic-actor pattern adds a review loop between execution and plan update.
Actor (Codex): Produces output against a fixed acceptance rubric. Critic (Claude Desktop): Evaluates the output against that rubric before any plan update or integration.
The critical design requirement: the rubric must be explicit and shared, not inferred from session context. If the critic doesn't have the rubric in its context — verbatim, not summarized — the critique degrades into vague feedback that the actor cannot act on.
Failure mode: A critic without context approves drift (it evaluates what it received, not what was intended). An actor that ignores structured feedback loops — because the feedback wasn't actionable enough — stops improving across iterations.
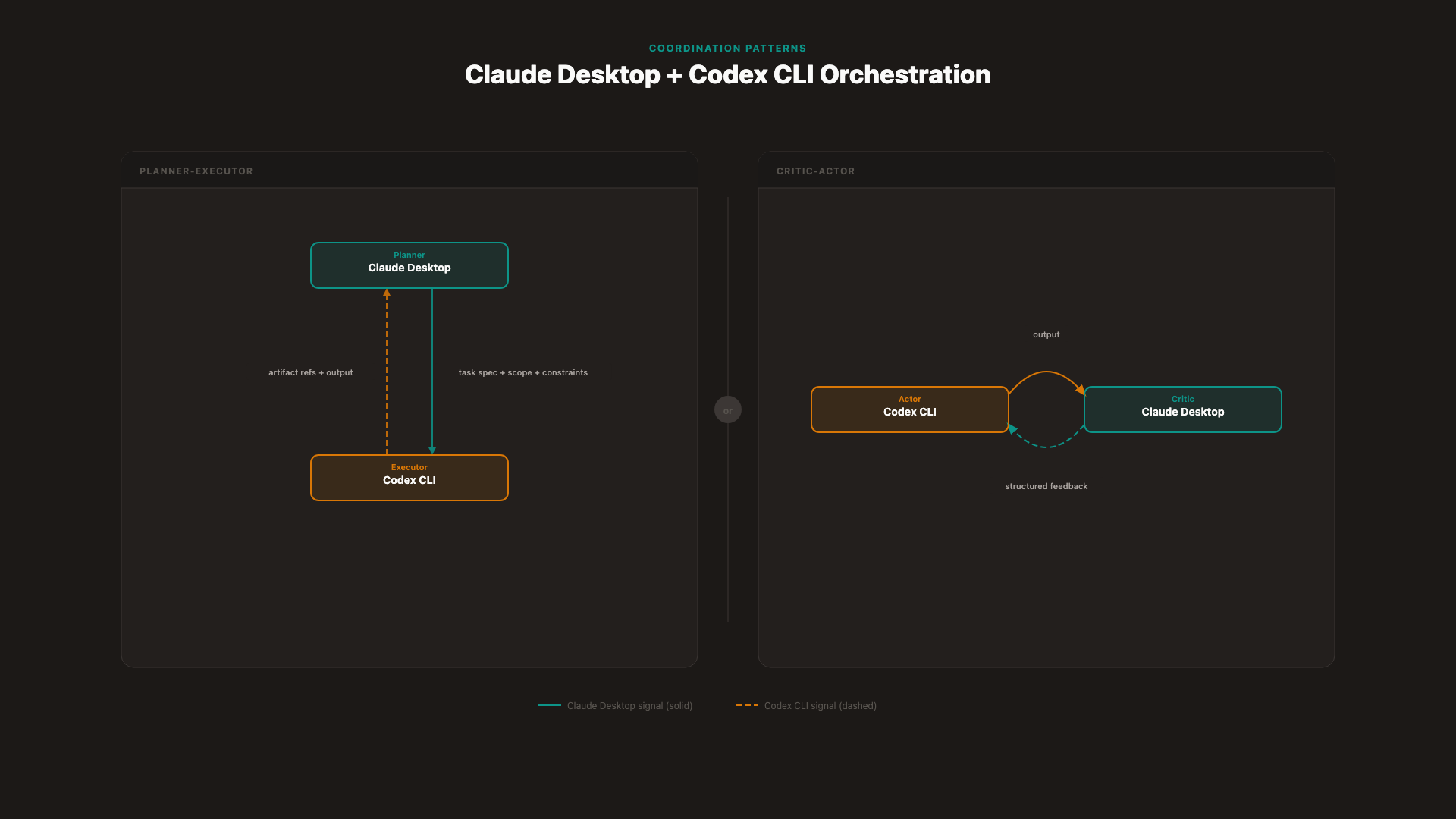
Pattern 3 — Specialist-Coordinator
For larger tasks with genuinely independent domains, a specialist-coordinator pattern distributes implementation across multiple Codex instances while Claude Desktop coordinates output and resolves conflicts.
Multiple Codex specialists: Each instance handles a domain-specific scope — authentication, data layer, API layer — with no knowledge of what the other specialists are doing.
Claude Desktop (Coordinator): Integrates specialist outputs, resolves cross-cutting concerns, and detects conflicts before integration.
Boundary rule: Specialists operate on isolated scopes. They don't know about each other. Cross-cutting changes — anything that touches a shared file or module — route to the coordinator, not to two specialists concurrently.
Failure mode: Two specialists modifying shared infrastructure produces conflicting edits that neither specialist can resolve, because neither has visibility into the other's scope [28]. The coordinator is the only agent with the full picture.
Clear roles solve the jurisdiction problem. They don't solve the handoff problem — what state actually moves between agents, and in what form.
Handoff Contract Design — What State You Pass Between Agents
A handoff contract is not a summary. It is a structured transfer of verified state that allows the receiving agent to continue work without having to infer, reconstruct, or hallucinate context from the previous session.
Most multi-agent coordination failures at the handoff boundary trace back to one pattern: agent A writes a prose description of what it did, and agent B fills the gaps with assumptions [13] [14]. Google's ADK team calls the alternative "narrative casting" — the handoff passes exactly the context the next agent needs to make its next decision, not a transcript of what the previous agent thought [11].
Evidence-Based vs Summary-Based Handoffs
Summary-based handoff (the failure pattern):
"I implemented the authentication module. It handles OAuth and session management. The tests pass. You should now work on the data layer."
The receiving agent has three problems: it doesn't know which files were modified, it can't verify what "tests pass" means (which tests? against what criteria?), and it has no explicit constraint from the previous session to carry forward.
Evidence-based handoff (the correct pattern):
"Completed:src/auth/oauth.ts(diff:auth/pr-23.diff). Tests:auth.spec.ts— 12/12 pass (run ID:test-2026-05-03-auth). Open constraint: session expiry logic deferred; seeopen-questionsfield. Next task:data-layer-connection, scoped tosrc/db/connection.tsonly."
The receiving agent can verify every claim. The constraint didn't get lost. The scope is bounded.
The Handoff State Structure
A minimal, effective handoff contract has the following fields:
{
"task-id": "auth-oauth-implementation",
"objective": "Implement OAuth 2.0 flow in src/auth/oauth.ts",
"constraints": [
"Session expiry: 24 hours (verbatim from plan v2)",
"No third-party OAuth libraries — internal implementation only"
],
"completed-steps": [
{
"step": "OAuth flow implementation",
"artifact": "src/auth/oauth.ts",
"ref": "commit:a3f92bc"
},
{
"step": "Unit tests",
"artifact": "src/auth/auth.spec.ts",
"ref": "test-run:2026-05-03-auth-12/12"
}
],
"next-step": {
"task": "data-layer-connection",
"scope": "src/db/connection.ts only",
"acceptance-criteria": "Connection pool initialized; retries on failure; 3 integration tests pass"
},
"open-questions": ["Session refresh token behavior — deferred; requires product decision"]
}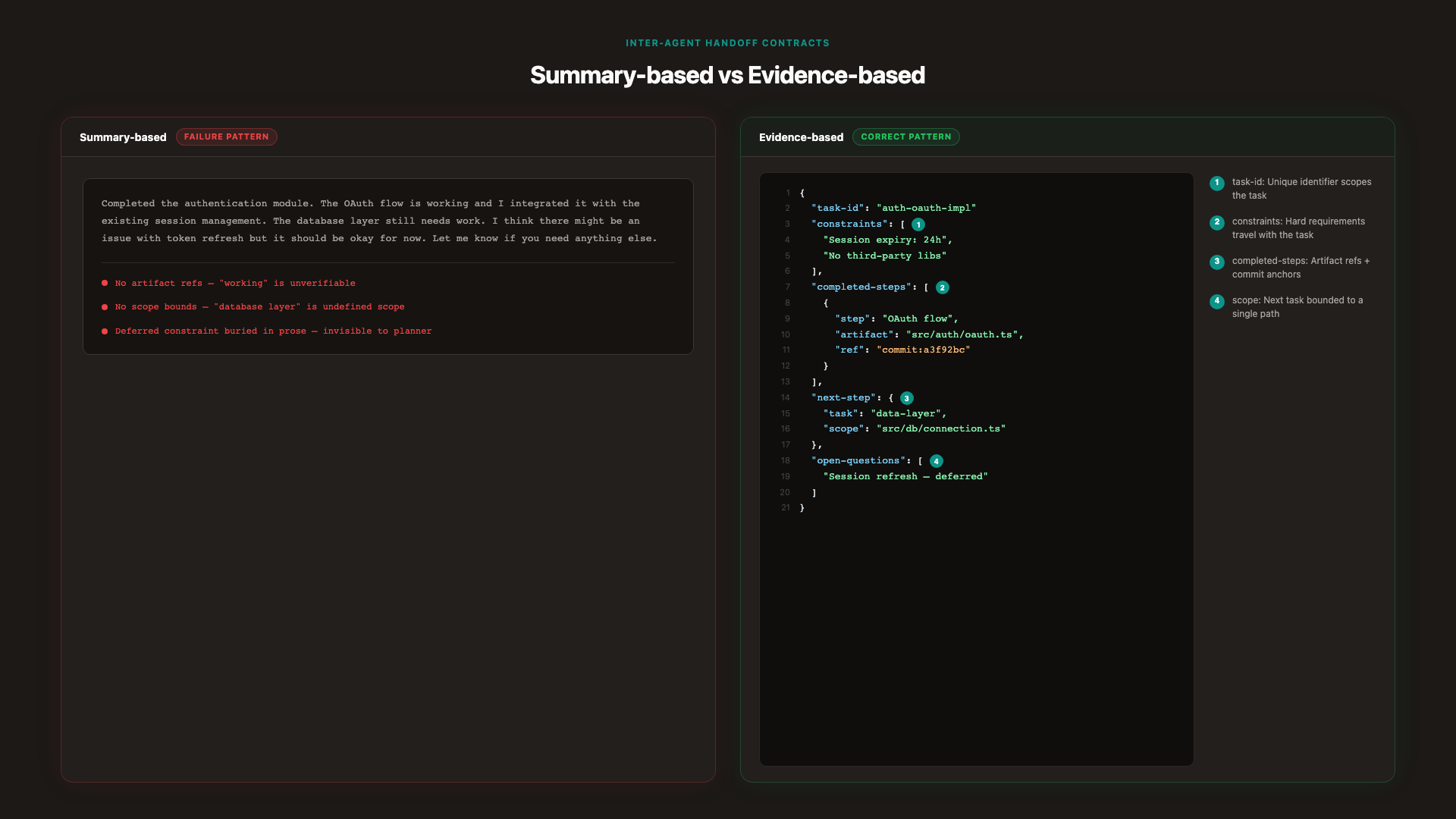
What to exclude: Full session transcripts, intermediate reasoning, exploratory dead-ends, agent-internal commentary. The receiving agent should be able to verify any claim against a named artifact. If a field's content cannot be verified, it doesn't belong in the contract.
Format discipline: Structured JSON or YAML, not prose. Prose summaries invite inference; structured fields require either a verifiable value or an explicit "unknown/deferred" marker. OpenAI's Agents SDK handoff mechanics and LangChain's handoff implementation both reinforce this pattern: the contract transfers control and responsibility, not conversation history [9] [10].
A well-formed handoff contract resolves what to pass. Context discipline resolves how much — and what each agent is allowed to see from the broader system.
Context Discipline — What Each Agent Sees (and What It Doesn't)
Context is not free. Every token an agent receives is a token it must process, weigh, and potentially act on. In multi-agent systems, over-sharing context between agents is one of the fastest paths to incoherence — not because more context is wrong in principle, but because context that's irrelevant to the current task becomes noise that the agent will try to reconcile with the task spec, usually incorrectly.
Google's ADK framework makes context curation a first-class design principle: each agent's view of the system should be scoped to what it needs to make the next decision correctly — no more, no less [11].
The Context Bloat Failure Mode
When an executor agent inherits the full planning thread — 3,000+ tokens of architectural reasoning, constraint trade-offs, exploratory dead-ends, and context about other subtasks — it doesn't receive "more information." It receives a race condition.
The agent will attempt to reconcile all of it with its current task spec. If there's a conflict — and in long planning threads, there usually is one — the agent tends to anchor on the most recent signal, not the most authoritative one [18]. The result: a Codex instance rewrites a function that was already correct, because the planning thread made it look like a problem worth solving.
A concrete scenario: a planning session establishes that a connection pool should use exponential backoff. Later in the session, there's discussion about simplifying retry logic for a different component. Codex, receiving the full session context, conflates the two — and implements simplified retry logic in the connection pool, overriding the original constraint.
Curating the Agent's View
Claude Desktop (Orchestrator) context includes:
- The canonical plan and dependency graph
- Cross-agent state: which subtasks are complete, which are in progress, which are blocked
- Open questions and unresolved constraints
- The output contracts from completed subtasks (artifact refs, not the full artifacts)
Claude Desktop does NOT receive: Raw implementation code from executors (it reviews summaries and artifact refs), full session history from individual Codex runs, or intermediate reasoning from other agents.
Codex (Executor) context includes:
- The task spec for this subtask only (objective, scope, constraints, acceptance criteria)
- The specific files it is authorized to modify
- The acceptance criteria it must satisfy
Codex does NOT receive: Other agents' outputs, the full planning thread, the rationale for other subtasks, or context about what specialist agents on parallel tracks are doing.
For projects that use a task management layer as the handoff medium — where task descriptions serve as source-of-truth briefs and task comments carry the audit trail — this structure maps naturally: the executor's context is the task spec; the coordinator's context is the work unit view [33].
Token Budget Management
Set a per-agent context budget proportional to task complexity, not available window size. Codex running a bounded implementation task doesn't need 100K tokens of context; it needs the task spec, the relevant file, and the acceptance criteria — typically under 2,000 tokens for a well-scoped subtask.
Prefer artifact references over inline copies. "See src/auth/oauth.ts, lines 42–67" is better context than pasting the file — the agent can fetch the relevant section if it needs it; it cannot un-read 500 lines it didn't need.
For parallel Codex instances: isolate each instance's context to its subtask entirely. Merge at the coordinator level only, after each instance has returned its output with artifact refs. The coordinator reconciles; the specialists don't [28].
Context discipline prevents overload. But it doesn't catch the errors that slip through a well-formed handoff. That's what verification gates are for.
Verification Gates — Testing Between Agents, Not After
Verification in multi-agent systems is not a post-hoc QA step. By the time a failure reaches end-to-end testing, it has typically propagated through two or three agent interactions, each of which compounded the original error. The Resilient LLM Agents framework identifies inter-agent verification — with least-privilege access and explicit input/output validation at each boundary — as a primary defense against cascading failures in multi-agent pipelines [30].
The design principle: verify at the boundary, not after all the boundaries have been crossed.
What to Verify at Each Handoff Boundary
Before Codex execution (task entry gate):
- Is the task spec complete? Is the objective unambiguous? Are constraints explicit and verbatim (not summarized)?
- Is the scope bounded to a named set of files or modules?
- Are the acceptance criteria present, testable, and not conditional on other subtasks' completion?
A task that fails this gate does not enter the executor queue. It goes back to the planner for clarification.
After Codex execution, before Claude Desktop review (output gate):
- Artifact integrity: does the output reference actual files and diffs? Are the file paths correct?
- Scope compliance: did the implementation stay within the authorized scope? Run a diff check against the task spec's named files.
- Test passage: do the unit tests for this subtask pass? Not the full system — the subtask-level tests specified in the acceptance criteria.
A task that fails this gate does not advance to the planner review. It goes back to Codex with a specific failure description, not a summary.
Before plan update by Claude Desktop (plan revision gate):
- Evidence completeness: does the completed subtask output include verifiable artifact refs for every completed step?
- Open question resolution: are all open questions either resolved or explicitly marked as deferred with a reason?
- Constraint carry-forward: are constraints from the original plan preserved or explicitly superseded?
Staged Rollout Gates
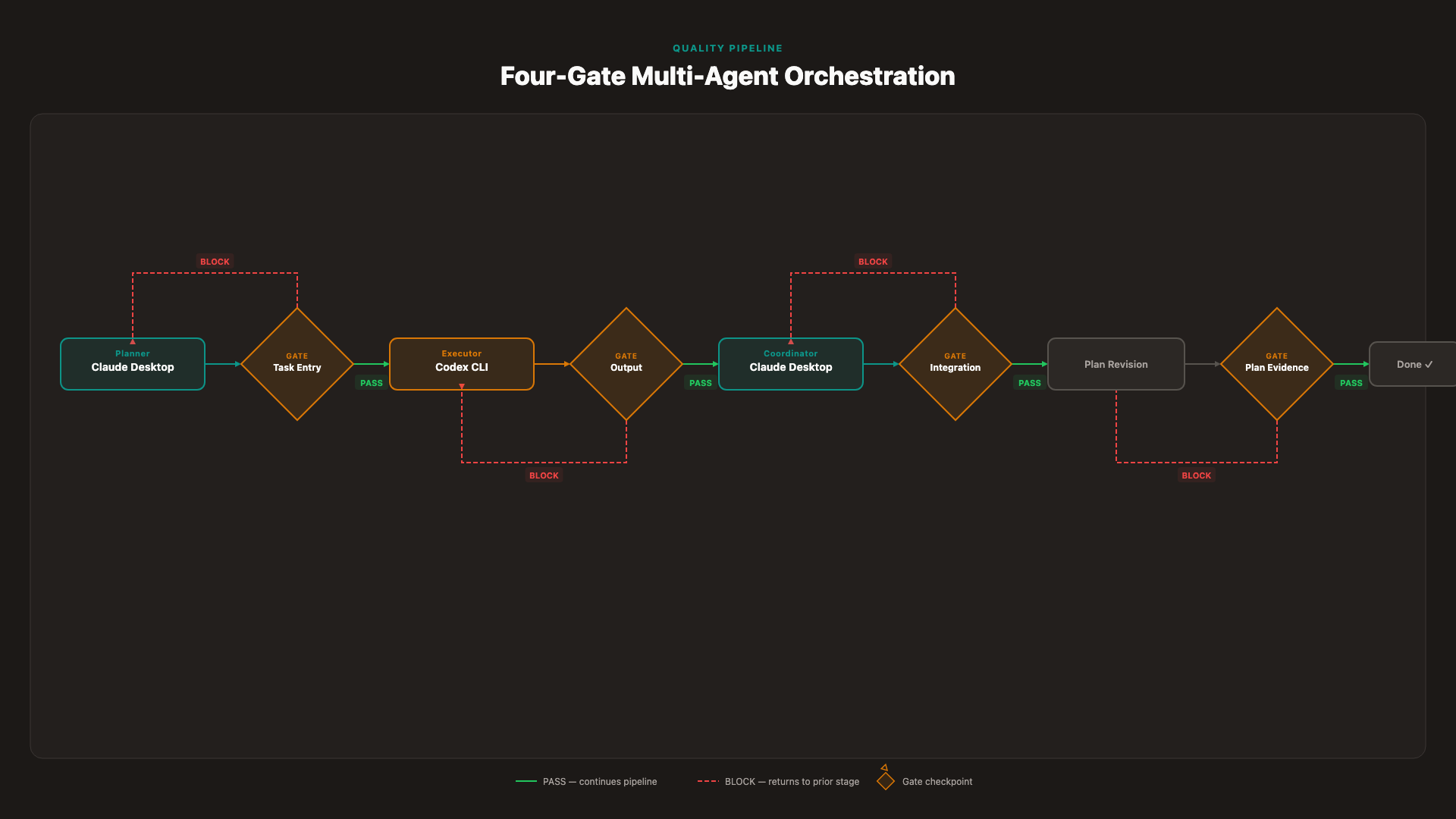
Gate 1 — Task Entry: No task enters an agent queue without bounded scope and explicit constraints. The planner is responsible for producing task specs that pass this gate before any handoff to Codex.
Gate 2 — Handoff Output: No output leaves an agent without a verification check against acceptance criteria. Codex is responsible for self-verification against the task spec before returning output; the coordinator verifies the artifact refs.
Gate 3 — Integration: No cross-agent artifact is merged without conflict detection. For parallel Codex instances, the coordinator runs a diff-aware merge check against all pending outputs before integration.
Gate 4 — Plan Revision: Plan revisions require evidence from the artifact, not summary from the agent. If a subtask's completion triggers a plan change, the change must reference the specific artifact that justifies it.
DAG-based workflow orchestration systems formalize this as verification nodes — explicit decision points in the execution graph where the system must pass a check before the next node can execute [32]. The gate model translates this into a discipline for manual and semi-automated multi-agent setups: no agent proceeds until the previous agent's output is verified. For architectural enforcement patterns, see enforcing AI architectural patterns with MCP.
Observability matters here. Production monitoring of multi-agent systems — tracking gate pass/fail rates, artifact verification outcomes, and plan drift metrics — gives you leading indicators of coordination failure before it becomes visible in system output [31].
Gates catch errors at the boundary. The failures that survive a well-gated system are the ones that emerge inside — drift, hallucination, and conflicting edits. Here's the defense playbook.
Failure Mode Defenses — Drift, Hallucination, and Conflicting Edits
Even well-architected systems with clean handoffs and active verification gates will encounter failures. The MAST taxonomy identifies coordination-related failures as the plurality — but within that category, three patterns account for the majority of incidents in code-generation multi-agent setups: drift, hallucination, and conflicting edits [24]. Each has a distinct detection signal and a specific mitigation.
Drift — When Output Diverges From the Original Plan
What it looks like: The system produces output that is plausibly correct but no longer matches the original plan. Functionality is added that wasn't specified. Scope expands across iterations. Constraints from the original plan are quietly dropped.
Detection: Run a plan-output diff at each Gate 2 check. Compare the completed subtask's output scope against the task spec's authorized scope. Divergence greater than 20% of scope — measured by files modified or functions changed relative to spec — triggers a block and forces re-planning [21].
Mitigation: The planner (Claude Desktop) holds the canonical plan and is the only agent authorized to revise it. The canonical plan lives in a structured artifact — not in session history — so any agent can be given a reference to the current version without relying on session memory. Executor agents receive task specs derived from the plan, not the plan itself, so they cannot modify it by changing their output.
Goal drift and "sycophantic drift" — where agents optimize for appearing aligned rather than being aligned — are documented failure modes in multi-agent systems [20]. The defense is a plan that is externalized, versioned, and independently verifiable, not one that lives in any single agent's context.
Hallucination — When an Agent Invents Facts or Artifact Refs
What it looks like: A handoff contract references a file that doesn't exist, a test run that never happened, or a constraint decision that was never made. The receiving agent proceeds on the basis of fabricated evidence, compounding the error.
Detection: Verify every artifact reference in a handoff contract against the actual file system or test run log before the contract is accepted. A reference to commit:a3f92bc should resolve to an actual commit. A reference to test-run:2026-05-03-auth should resolve to an actual test result. References that don't resolve fail Gate 2. [30]
Mitigation: Evidence-based handoff contracts (the design from the handoff section) are the primary defense. An agent that can only pass verifiable artifact references cannot pass hallucinated ones — not because it's incapable of generating them, but because the gate will reject them. The structure of the contract makes hallucination detectable rather than invisible [14] [20].
Conflicting Edits — When Two Agents Modify the Same Artifact
What it looks like: Two parallel Codex instances, each working within their designated scope, independently modify a shared module — a utility function, a configuration file, a database schema. Each output is locally correct. Together, they are incoherent.
Detection: File lock protocol or diff-aware merge check at Gate 3 (integration). Before any parallel output is merged, the coordinator runs a conflict detection pass across all pending outputs — comparing modified file lists across all instances [28].
Mitigation: Specialist agents operate on isolated scopes (Pattern 3 — Specialist-Coordinator). Cross-cutting changes — anything that touches a shared module or file — are identified by the planner at task decomposition time and routed to the coordinator as a single sequential task, never distributed to two parallel specialists concurrently. The isolation is enforced at task entry (Gate 1): a task spec that names a shared file as its scope should trigger coordinator routing, not specialist assignment.

| Failure | Detection Signal | Mitigation Pattern | Gate |
|---|---|---|---|
| Drift | Plan-output scope diff > 20% | Externalized canonical plan; executor scope lock; planner-only plan revisions | Gate 2 (output), Gate 4 (plan revision) |
| Hallucination | Artifact refs fail resolution | Evidence-based handoff contracts; ref verification before acceptance | Gate 2 (output), Gate 3 (integration) |
| Conflicting edits | Parallel outputs touch same file | Specialist scope isolation; coordinator routes shared-file tasks; conflict detection before merge | Gate 1 (task entry), Gate 3 (integration) |
Three failure modes, three detection patterns, three mitigations — each tied to a specific gate. Put them together with the contracts, the role boundaries, and the context discipline, and you have the full architecture stack.
Building Multi-Agent Systems That Stay Coherent
Multi-agent code orchestration fails not because the models aren't capable, but because the architecture isn't disciplined. Six layers compound into either a coherent system or a failing one: runtime assignment, role separation, handoff contract design, context discipline, verification gates, and failure mode defenses.
The teams that ship coherent multi-agent systems don't debate which model is smarter. They spend their design time on the contracts between agents, not the agents themselves. The runtime decision is the first constraint. Role separation is the second. Handoff contract design is the third. Everything after that — context discipline, verification gates, failure mode defenses — is the work of enforcing those contracts under real conditions.
The MAST finding is the anchor: 36.94% of multi-agent failures are coordination failures [24]. Architecture solves them. Model upgrades don't. For guidance on scaling these patterns to production systems, read scalable coding with AI agents.
References
[1] Orchestrate teams of Claude Code sessions — Claude Code Docs (2026)
[2] Multi-agent orchestration for Claude Code in 2026 — Shipyard (2026)
[3] Intelligent automation and multi-agent orchestration for Claude Code — GitHub / wshobson (2026)
[4] The Code Agent Orchestra: What makes multi-agent coding work — Addy Osmani (2026)
[5] Agent SDK overview — Claude Code Docs (2026)
[6] Claude Managed Agents overview — Claude API Docs (2026)
[7] Claude Desktop App vs Terminal: Which Setup Is Right for Agentic Work? — MindStudio (2026)
[8] Claude Code vs Codex App in 2026: Local Agent Pairing vs Cloud Agent Orchestration — Developers Digest (2026)
[9] Handoffs — OpenAI Agents SDK (2026)
[10] Handoffs — LangChain Docs (2025)
[11] Architecting efficient context-aware multi-agent framework for production — Google Developers Blog (2025)
[12] Handoff — Encyclopedia of Agentic Coding Patterns, AI Pattern Book (2025)
[13] How Agent Handoffs Work in Multi-Agent Systems — Towards Data Science (2025)
[14] AI Agent Handoff: Why Context Breaks & How to Fix It — XTrace (2025)
[15] Designing a State-of-the-Art Multi-Agent System — Polarix (2025)
[16] Multi-Agent System Patterns: Architectures, Roles & Design Guide — Medium (2025)
[17] PAT: Planner Executor — CAST AI Framework (2025)
[18] Planner-Executor Agentic Framework — Emergent Mind (2025)
[19] AI Agent Failure Modes: What Goes Wrong and Why — NimbleBrain (2025)
[20] Why do Multi Agent LLM Systems Fail? — HuggingFace Blog (2025)
[21] 7 AI Agent Failure Modes and How to Prevent Them — Galileo (2025)
[22] The Dark Psychology of Multi-Agent AI: 30 Failure Modes — Medium (2025)
[23] Why Multi-Agent LLM Systems Fail & How to Fix Them — Redis Blog (2025)
[24] Why Do Multi-Agent LLM Systems Fail? — arxiv / MAST Taxonomy (2025)
[25] CLI — Codex, OpenAI Developers (2026)
[26] Use Codex with the Agents SDK — OpenAI Developers (2026)
[27] Building Consistent Workflows with Codex CLI & Agents SDK — OpenAI Developers (2026)
[28] Running Multiple Codex Agent Instances: Parallel Orchestration Patterns — Codex Blog (2026)
[29] Oh-My-Codex (OMX): The Community Orchestration Layer — Codex Blog (2026)
[30] Architecting Resilient LLM Agents — arxiv (2025)
[31] Detecting AI Agent Failure Modes in Production — Latitude (2026)
[32] What Are Agentic Workflows? Design Patterns & When to Use Them — Neo4j (2025)
[33] Agiflow project-mcp integration — internal reference (generic task routing example)
More to read
Why Your Team's AI Coding Tool Breaks at Scale (And It's Not the Model)
Every team benchmarks AI coding tool quality. Almost nobody asks where the control surface lives or who owns shared state when the session ends. That second question is the one that breaks teams at scale.
10 min readSpec-Driven Development Tools: Where AI Project Memory Lives Is the Only Decision That Matters
The spec-driven development tool landscape grew from 6 to 13 tools in a single community repo, not because the field is converging, but because three communities are building on incompatible assumptions about where AI project memory should live.
11 min read5 Dimensions That Separate a Real MCP Integration From a Read-Only Wrapper
Nearly every PM platform ships an MCP server now. Here is a 5-dimension framework for telling whether a given integration will change how your team works or just add a checkbox.
10 min readPut this project board inside ChatGPT
Open Agiflow in ChatGPT to plan campaigns, create tasks, and check what needs attention. Create a free Agiflow account when you are ready to keep the board for your team.