Introducing the Agiflow CLI: Scaling AI Agents Across Machines
GitHub Actions was never built for the fast closed loop an agent needs — going back, redoing a step, fixing its own work. Local agent fan-out solved the loop on one laptop and broke on two. The Agiflow CLI is the convenience wrapper we use internally to drive workflow locks, work units, and artifacts through the Agiflow API — so agents on different machines can pull the same backlog without stepping on each other.
We build a lot of products on Agiflow, and we use Agiflow itself to plan and ship them. Once we started running AI coding agents against that backlog, executing work mattered as much as organising it. This post is how we got from "GitHub Actions plus a Python script" to a small CLI we run on every machine — not a new product launch, just the gateway we use internally to talk to the Agiflow API.
Two earlier posts in this series cover the prerequisites: work units for grouping related tasks into chunks an agent can carry from spec to PR, and agent role separation for assigning the right model to the right slice of the work. This post picks up where those leave off — once you have well-shaped work units and well-shaped agents, how do you actually run them across more than one machine without producing duplicate branches and lost evidence?
Why GitHub Actions wasn't enough
Our first instinct was to codify the agent workflow as GitHub Actions jobs. It worked for a week. The problem wasn't reliability or granularity — it was that Actions isn't built for the closed loop an agent actually runs.
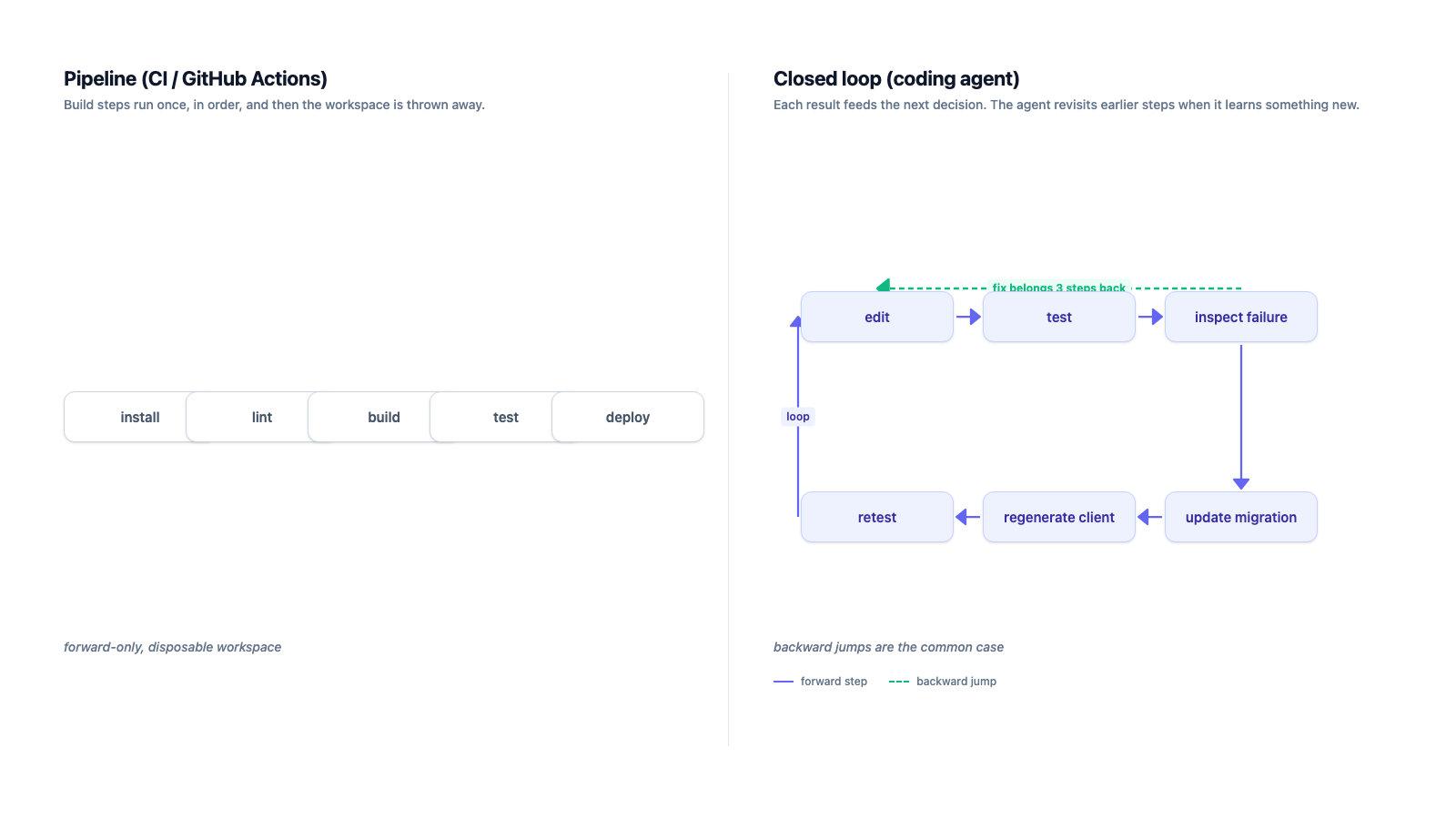
The unit of execution was wrong. Actions treats a run as a disposable pipeline. Agents need a persistent working session. A typical run did not look like install → lint → test → done; it looked like edit → test → inspect failure → update migration → regenerate client → retest one package → run integration test → inspect logs → rewrite the original edit. That loop happens dozens of times inside a single work unit, and most of those iterations are backwards — the agent decides the bug it just hit was actually introduced three steps ago.
In Actions, every reversal becomes expensive. A failed test means a new job, a fresh checkout, dependency restore, cache lookup, environment setup, and only then the command the agent actually wanted to run. Even when caching works, the agent loses everything that makes local coding cheap: warm TypeScript state, the local database the migration just ran against, the previous command's stdout still in scrollback, generated files that were intentionally not committed yet, and the exact shell history around the failure. For a human reviewing CI, that statelessness is a feature. For an agent whose value comes from rapid correction, it turns a tight feedback loop into a remote-control workflow with multi-minute latency between every "what just happened?" and the next attempt.
The real lesson was that CI is a verifier, not an agent runtime. We still want CI to tell us whether a branch is acceptable. We do not want CI to be the place where the agent discovers, reasons, backtracks, and repairs its own work. Three execution surfaces, three different jobs:
| Surface | Overhead between shell commands | Workspace state | Backward steps | Right job |
|---|---|---|---|---|
| GitHub Actions | minutes (job spinup, checkout, dependency restore, cache lookup) | fresh on every run | expensive, often a whole-job rerun | verifying a branch a human or agent already finished |
| Single-machine daemon | seconds (the shell itself) | warm, persistent across iterations | cheap | one agent iterating on one work unit |
| Agiflow CLI runner (per machine) | seconds (the shell itself) | warm, persistent across iterations | cheap | many agents iterating on the shared backlog |
pnpm test --filter billing" and "the test process actually starts." On Actions, that dead time is dominated by infrastructure overhead. On a local runner, it's just the shell. The agent's loop still takes minutes, but the minutes are spent on reasoning and code execution, not on rehydrating a workspace.
So we wrote our own runner — a small daemon that asked Agiflow for the next work unit, spun up an agent with the right context, and let it iterate locally until the work unit was done. Same machine. Same filesystem. Warm caches. The infrastructure between the agent's decisions disappeared, so the only time it spent was the time it was actually doing useful work. On one developer's machine it was magic.
The multi-machine version wasn't
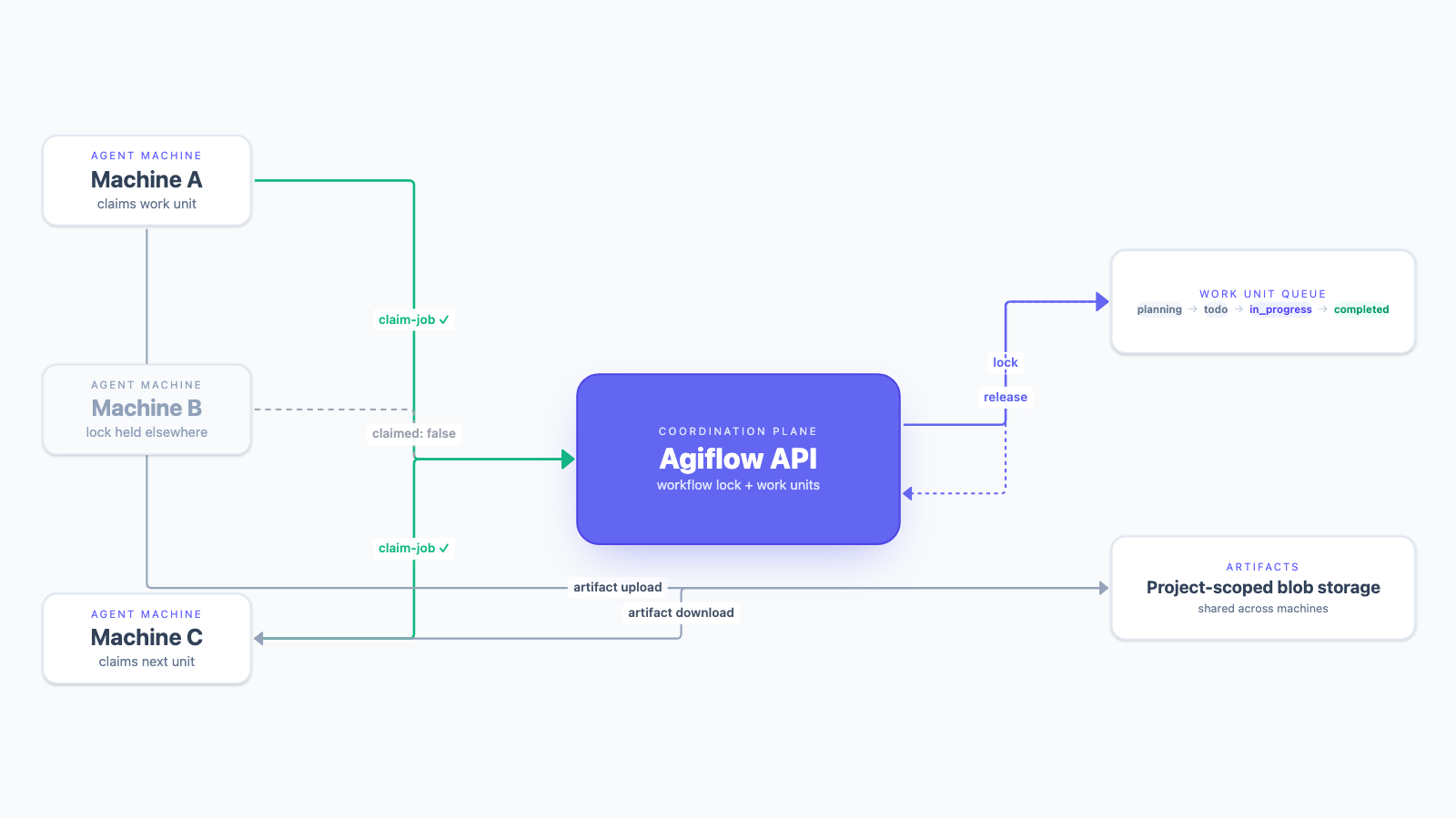
The one-machine version relied on a quiet assumption: local state was enough because there was only one actor. The daemon kept a small record of "currently running" work units, and that record was effectively true.
The moment a teammate ran the same daemon on their laptop, the assumption collapsed. Both runners could observe the same backlog item as available, both could start work, and both could push branches that looked legitimate in isolation. The damage appeared later — when two agents had modified the same schema, generated different migrations, or interpreted the same task boundary differently. The loser was not always obvious. Sometimes the second branch had the better implementation but the first branch owned the task state. Sometimes both were partially correct and a human had to merge the intent manually.
Our first fixes were local coordination disguised as distributed coordination. Claim timestamps helped until a laptop slept. Heartbeats helped until a process died between writing code and releasing the claim. Expiry windows helped until two machines disagreed about time, or a long-running test made a healthy agent look dead. Each patch reduced one failure mode and introduced another. The problem was not the heartbeat interval. The problem was that the lock did not live with the backlog.
The fix wasn't a smarter daemon. The fix already existed inside the Agiflow API — workflow locks, atomic claims, artifact storage. If a work unit is the unit of planning, assignment, progress, and review, then it also has to be the unit of execution ownership. What we were missing was a convenient way to call those endpoints from every laptop, runner, and CI box without re-writing the auth and JSON plumbing each time.
A thin gateway, not a new product
@agiflowai/cli is that gateway. The binary, agiflow-cli, is not a second orchestration system. It does not maintain a local queue, invent a new state machine, or keep its own database of claims. It calls the Agiflow HTTP API — the same API the Agiflow web app uses — and prints the result in a form that either a human or a script can consume.
That makes the CLI boring in the best possible way. Two modes, one binary:
- Human mode — readable terminal output, device-code login (
agiflow-cli login), helpful errors. What you reach for when you want to inspect a work unit by hand. - JSON-only mode — every
automation,project,task,work-unit,member, andtask-commentcommand speaks--format jsonso shell scripts can pipe it throughjq. No scraping pretty tables, no parsing English error messages, no special CI-only client library.
The environment variable contract is part of the design. AGIFLOW_API_KEY, AGIFLOW_ORGANIZATION_ID, AGIFLOW_PROJECT_ID, AGIFLOW_WORK_UNIT_ID, AGIFLOW_TASK_ID, and AGIFLOW_DEVICE_ID let us move the same runner script between a laptop, a spare workstation, and a hosted runner without changing the script body. The machine supplies identity and scope; the CLI supplies the API boundary.
The locking semantics aren't in the CLI — they're in the API. The CLI just makes them ergonomic.
Workflow locks, surfaced as commands
The workflow command group is the low-level primitive. Use it when a caller already knows exactly which work unit it wants to execute and wants exclusive ownership:
agiflow-cli workflow create --work-unit <id> --name <run-name>says: "I am starting a run against this work unit; reject any competing run until I release it."agiflow-cli workflow release <workflow-id> --status completed|failedsays: "This run is finished; record whether it completed or failed, and make the work unit available for the next state transition."
The shape is deliberate. We get a lock with an auditable lifecycle, not a boolean field called claimed. The workflow id is the durable handle for cleanup, and unreleased ownership is worse than a failed job — it hides work from every other runner. Any realistic runner should treat release as part of execution, not as a courtesy after it:
cleanup() {
if [ -n "${workflow_id:-}" ]; then
agiflow-cli workflow release "$workflow_id" \
--status failed --format json >/dev/null || true
fi
}
trap cleanup EXITShell isn't the ideal orchestration language. The point is that the ownership model is explicit enough that even shell can use it safely.
The CLI exposes the lock at two levels, and which one to call depends on whether you're targeting a known work unit or polling for the next available one:
| Command group | Caller | When to use | On contention |
|---|---|---|---|
workflow create / release | Knows the work unit id up front | Manual run, scripted run against a specific work unit, custom orchestration | API rejects with an error |
automation list-jobs / claim-job / release-job | Polling worker, no specific job in mind | Multi-machine runner loops, CI-side automation, agent fleets | Returns claimed: false as data |
For runners we usually start one level higher than workflow. The automation command group is designed for polling workers — same underlying lock, different caller experience. If another machine wins the race, claim-job returns a normal JSON response with claimed: false instead of throwing.
That distinction matters operationally. In a multi-runner system, losing a claim is not an error — it's the common case. Ten machines can ask for the next available job at roughly the same time; one should win, nine should calmly continue polling. Treating that as a thrown exception pollutes logs, triggers false alarms, and trains people to ignore real failures.
A real runner loop handles three states explicitly. Each is a normal JSON response, not an exception:
| State | list-jobs .items | claim-job .claimed | claim-job .workflowId | Runner action |
|---|---|---|---|---|
| Backlog empty | [] | n/a | n/a | sleep, poll again |
| Lost the race | non-empty | false | empty | drop, poll again |
| Claimed | non-empty | true | present | run the agent, release on exit |
job=$(agiflow-cli automation list-jobs \
--org "$AGIFLOW_ORGANIZATION_ID" --project "$AGIFLOW_PROJECT_ID" \
--status todo,in_progress --limit 1 --format json)
job_id=$(printf '%s' "$job" | jq -r '.items[0].id // empty')
job_kind=$(printf '%s' "$job" | jq -r '.items[0].kind // empty')
[ -n "$job_id" ] || exit 0 # backlog empty
claim=$(agiflow-cli automation claim-job \
--org "$AGIFLOW_ORGANIZATION_ID" --project "$AGIFLOW_PROJECT_ID" \
--job-kind "$job_kind" --job-id "$job_id" \
--name "runner-$(hostname)" --device-id "$AGIFLOW_DEVICE_ID" \
--format json)
claimed=$(printf '%s' "$claim" | jq -r '.claimed // false')
workflow_id=$(printf '%s' "$claim" | jq -r '.workflowId // empty')
[ "$claimed" = "true" ] && [ -n "$workflow_id" ] || exit 0 # someone else won
# ...run the agent against the work unit...
agiflow-cli automation release-job \
--org "$AGIFLOW_ORGANIZATION_ID" --project "$AGIFLOW_PROJECT_ID" \
--workflow-id "$workflow_id" --status completed --format jsonWe poll for todo,in_progress rather than planning because planning work hasn't been groomed yet — runners should not start something a human or upstream agent is still scoping. That filter is the cheapest place to enforce backlog readiness.
This is the core scaling pattern: polling is cheap, claiming is atomic, and losing the race is represented as data. The runner needs no leader election, no shared filesystem, no clock-skew handling — the API is the coordination point. Every machine runs the same loop and the database in front of the API already knows which work units are in flight.
Artifacts close the handoff loop
Locking is half the problem. The other half is what comes out of an agent's run. The branch contains the code, but it rarely contains the evidence: a Playwright trace, a browser screenshot, a coverage report, a migration diff, a benchmark result, a structured review note. These outputs are too noisy for git and too important to leave on a laptop.
Generic object storage solves half of that. A bucket can store a file, but it doesn't know which work unit produced it, which project it belongs to, or which reviewer needs it. Agiflow artifacts are project-scoped blobs attached to work units, so the output travels with the unit of work — not as an unlabelled path in a Slack message or a CI log nobody opens twice.
That matters when work crosses machines. A backend agent uploads a generated API report. A frontend agent picks it up later while implementing the UI against the same work unit. A tester attaches screenshots and traces after e2e verification. A human reviewer inspects the same evidence from the work-unit record without asking which runner produced it or whether the file still exists on that machine.
agiflow-cli artifact upload ./playwright-report.zip \
--project "$AGIFLOW_PROJECT_ID" \
--name playwright-report.zip --type application/zip --format json
agiflow-cli artifact download "$ARTIFACT_KEY" \
--project "$AGIFLOW_PROJECT_ID" --output ./playwright-report.zipThe important part isn't the upload syntax. It's that execution output becomes addressable by project and work unit, not by machine.
What scaled execution looks like now
The result is not a glamorous distributed system. It is a small amount of coordination in the right place. Every runner uses the same backlog, the same lock primitive, the same artifact store, the same JSON contract. A developer's laptop and a CI box differ in credentials and capacity, not in orchestration logic. Each contributor — human or agent — is a member created with agiflow-cli member create. Each machine identifies itself with a stable --device-id. Work units flow through planning → todo → in_progress → completed without anyone manually assigning them.
That keeps the boundary honest. The CLI does not make agents better at understanding a task. It does not replace work-unit design, role separation, tests, or human review — those were the subjects of the earlier posts. The CLI solves a narrower problem: once the backlog is structured and agents have clear roles, how do multiple machines safely pull work without duplicating execution or losing the evidence they produce?
The CLI didn't replace our home-grown runner. It became the part of it we stopped maintaining: auth, retries, JSON parsing, lock semantics, artifact upload, machine identity — all delegated to one binary that talks to the API we were already going to call anyway. We still own the runner policy — which jobs to poll, how many agents to start, when to back off, how to report failure. That's the right split. Policy stays close to the team. Coordination lives in Agiflow.
Try it
The CLI is published on npm as @agiflowai/cli:
# one-off, no install
npx @agiflowai/cli --help
# or install globally
npm install -g @agiflowai/cli
agiflow-cli loginPoint it at your Agiflow API endpoint (VITE_INJECT_BACKEND_AGIFLOW_API_ENDPOINT or BACKEND_AGIFLOW_API_ENDPOINT), set AGIFLOW_ORGANIZATION_ID and AGIFLOW_PROJECT_ID, and the runner snippets above are ready to drop into a cron, a systemd unit, or a tmux pane on whatever machine has the warm caches.
More to read
The Four Things Claude Code Tasks Cannot Store — and Why Teams Hit That Wall
Claude Code Tasks shipped January 22, 2026 — a real, well-designed feature that persists agent work across sessions on one machine. Three months later, developers were still publishing workarounds. This post maps the four boundaries Tasks was designed to have, and tells you exactly when native Tasks is sufficient and when it is not.
11 min readRoadmap to Build Scalable Frontend Applications with AI: Atomic Design System, Token Efficiency, and Design Systems
Learn how to architect frontend applications that scale with AI assistance. Discover how atomic design methodology, component libraries, and design systems dramatically reduce token consumption while ensuring consistent, maintainable codebases.
18 min readCoordinating Multi-Task AI Workflows with Work Units: Building Complete Features in One Session
AI coding assistants excel at single tasks but struggle with multi-task feature coordination. Learn how work units + Project MCP enable structured AI agent workflows, reducing feature delivery time by 40% and maintaining context across 5-8 related tasks.
22 min readPut this project board inside ChatGPT
Open Agiflow in ChatGPT to plan campaigns, create tasks, and check what needs attention. Create a free Agiflow account when you are ready to keep the board for your team.