Spec-Driven Development Tools: Choose by Where Project Memory Lives
Spec-driven development tools are not converging on one winner. The useful decision is where durable project memory lives after the AI session ends: in specs, in git, or in an external MCP-connected board.
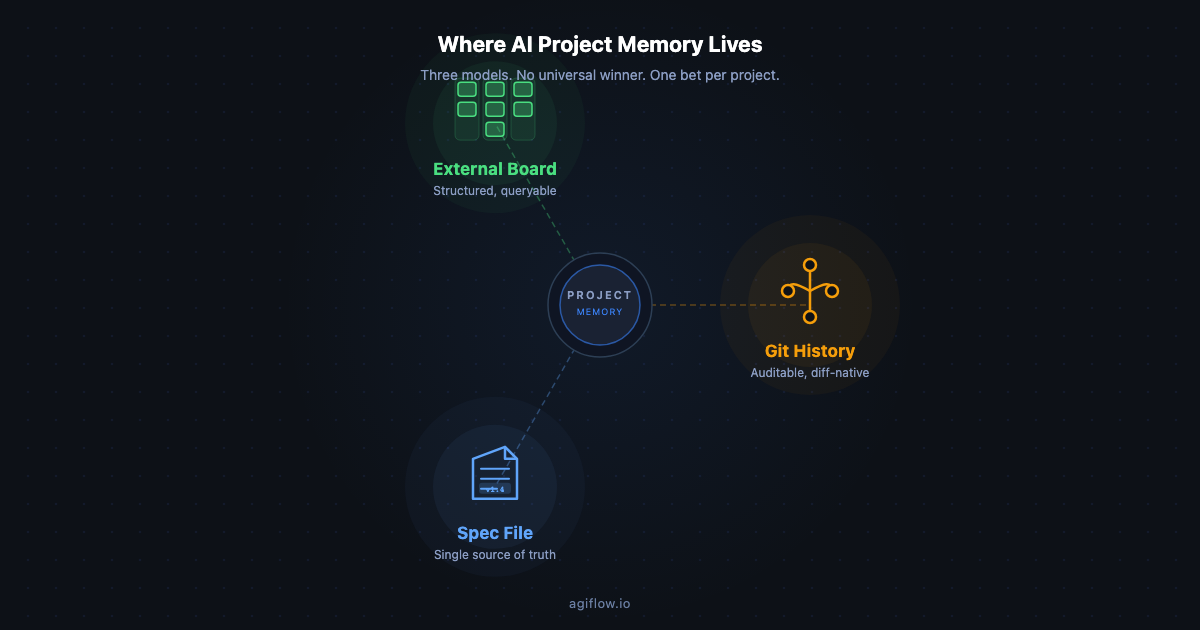
Spec-driven development tools are multiplying because teams are trying to solve different memory problems, not because the category has found one best workflow.
GitHub Spec Kit, OpenSpec, BMAD, Kiro, Taskmaster, Cursor rules, and board-based workflows all promise more reliable AI-assisted work. The mistake is comparing them feature by feature before answering the architectural question underneath: where does the work contract live after the AI session ends?
My answer is blunt. Choose the state boundary first. Then compare tools.
If you have already read why AI coding agents lose context across sessions, this is the ecosystem follow-on. Context loss is the symptom. Anthropic's context-engineering guidance frames context as finite, which is exactly why the durable record has to live somewhere more stable than the current prompt window [9].
Which Spec-Driven Development Tool Model Should A Team Choose?
Choose a spec-file model when one person or one small team can maintain version-controlled specs. Choose a repo or git-state model when commits, task files, and review logs already act as the durable audit trail. Choose an external board over MCP when work must survive across tools, people, agents, artifacts, approvals, and workflow locks.
| Model | Choose it when | Watch for |
|---|---|---|
| Spec-file model | Requirements, designs, tasks, and plans can live in version-controlled files that humans update deliberately. | Markdown drift after implementation changes. |
| Repo or git-state model | The team already trusts commits, branches, local task files, and review logs as the operating record. | Noisy commits and missing handoffs. |
| External board over MCP model | Several people or assistants need shared status, ownership, blockers, artifacts, approvals, and locks. | Extra service overhead if the task is short and solo. |
What Changed Since The Original Article?
The original article used a tool-count hook from a community comparison repo. The refreshed research found that exact count is no longer safe to reuse. The opened cameronsjo/spec-compare repository still presents itself as a comparison of six spec-driven development tools, while the wider category has kept moving through official repositories, vendor roundups, practitioner comparisons, and community threads [11] [12] [13].
That uncertainty is the point. Exact counts, star counts, pricing, and rankings are brittle in this market. The more durable update is structural: the tool set is still active, but the tools are not converging on one storage model.
As of the July 5, 2026 source sweep, GitHub Spec Kit describes a workflow with a constitution, specification, plan, tasks, and implementation commands, plus support for more than 30 AI coding agents [1]. OpenSpec now describes Stores beta as a way to share specs and changes across repositories, which complicates the older view that spec-first tools are only local markdown [3]. BMAD presents itself as a heavier AI-driven agile framework with specialized agents and adaptive planning depth [4]. Kiro supports requirements-first and design-first spec workflows, including requirements written in EARS-style notation [5]. Taskmaster positions itself as a task management system for AI-driven development with several tool modes [10].
Those are product facts and product claims, not proof that any one tool is universally better. They are enough to show why the first decision should be about state.
Model A: Spec Files Own The Work Contract
The spec-file model says the durable contract belongs in the repository as explicit documents: requirements, design notes, plans, tasks, project rules, and sometimes a constitution.
GitHub frames Spec Kit around executable specifications that guide implementation rather than treating the spec as throwaway planning prose [1]. GitHub's launch post also presents the workflow as one with human verification checkpoints around generated artifacts, and says the toolkit works with GitHub Copilot, Claude Code, and Gemini CLI [2]. OpenSpec uses proposals, specs, design, tasks, apply, and archive as its lifecycle vocabulary, and positions itself as lightweight, iterative, and brownfield-friendly [3]. Kiro's feature specs docs give the model a more IDE-native shape: requirements-first or design-first specs, with structured acceptance criteria when useful [5].
This model is strong when the spec is maintained like code. It gives the next session something concrete to read. It gives reviewers a visible artifact. It also keeps the work contract close to the implementation.
The failure mode is not mysterious. Practitioners complain about planning overhead, markdown drift, and a lack of brownfield examples in community threads [14] [15]. Treat that as qualitative language, not a market survey. The objection still matters because it names the operational risk: a spec that is not updated after implementation changes becomes a stale prompt with better formatting.
Use the spec-file model when the task is bounded, the team is small, and the people doing the work will keep the spec current. Do not use it as a substitute for live ownership, blockers, approvals, or artifact handoffs.
Model B: Repo And Git State Own The Durable Record
The repo-state model is the lowest-infrastructure answer. The source of truth is already in the development environment: files, branches, commits, local task notes, review comments, and logs.
This can work. A small team that commits cleanly, writes reviewable task files, and keeps implementation evidence close to code may not need a new service for every feature. The repo gives you a versioned record and a shared review surface.
The cost is discipline. A repo can preserve history without preserving meaning. A branch full of broad commits does not tell the next assistant why the work exists, what is blocked, which criteria were approved, or what artifact proves a change. That is why the local-task ceiling shows up in adjacent tooling too. The Claude Code task limitations article makes the same boundary visible: local task state can survive sessions on one machine, but it does not automatically become cloud state, team access, credential state, or artifact storage.
Repo state is often enough for solo developers, audit-first workflows, and short features where the pull request is the natural handoff. It is weaker when several agents or reviewers need to coordinate before code is ready to merge.
Model C: An External Board Over MCP Owns Shared State
The external-board model starts from a different assumption: the assistant should not be the system of record, and the repo should not be forced to carry live operational state.
MCP is the connection layer that makes this model practical. The Model Context Protocol docs define MCP as an open-source standard for connecting AI applications to external systems, including data sources, tools, and workflows [6]. The 2025-06-18 specification describes hosts, clients, servers, resources, prompts, and tools, and it explicitly calls out security and trust considerations [7]. Anthropic introduced MCP on November 25, 2024 as an open standard for secure two-way connections between data sources and AI-powered tools [8].
That does not mean MCP creates good memory by itself. It creates a connection path. The state model still has to be designed.
Agiflow fits here as an external state surface, not as a complete SDD framework. The first-party positioning is narrower: Agiflow is a commercial project board that connects external AI assistants over MCP. The assistant stays the agent. Agiflow supplies scoped board tools, prompt skills, shared state, artifacts, vault entries, and workflow locks [19].
That boundary is useful because it names what belongs where:
| Home | What belongs there |
|---|---|
| Spec files | Requirements, intended behavior, design notes, planning artifacts. |
| Git | Code history, implementation evidence, reviewable diffs, release record. |
| External board | Owner, status, blockers, approvals, artifacts, handoffs, vault entries, workflow locks. |
The honest limitation is overhead. An external board is unnecessary for a short solo change where the spec and commit are enough. It earns its place when the work crosses tools, sessions, machines, people, artifacts, or active locks.
What Each Model Costs Under Pressure
Every model sounds clean in a demo. The decision only gets useful when pressure enters the room.
| Pressure | Spec files | Repo or git state | External board over MCP |
|---|---|---|---|
| Session restart | Strong if the spec is current. | Strong if the relevant files and commits are obvious. | Strong if the assistant can query scoped task state. |
| Team sharing | Good when specs are reviewed like code. | Good when commits and reviews are disciplined. | Native, if the board is the source of truth. |
| Debugging transparency | Human-readable prose. | Auditable history. | Structured records, comments, artifacts, and lock history. |
| Setup cost | Low. | Low. | Higher, because a service must be maintained. |
| Multi-agent scale | Fragile without coordination rules. | Possible with strong branch and commit discipline. | Designed for shared access and explicit ownership. |
| Drift risk | Spec can lag implementation. | Commit history can preserve changes without decisions. | Board can become stale if the team will not maintain it. |
That last warning matters. A board that nobody updates is worse than a spec that nobody updates because it adds another place to check.
What Community Objections Reveal
Community threads are not neutral evidence, but they are useful vocabulary. The recurring objections are practical: too much ceremony, specs drifting from code, weak brownfield examples, planning quality that still produces poor implementation when the spec has gaps, and confusion between SDD as an approach and SDD as a package [14] [15] [16] [17] [18].
Those objections support the architectural view. If people say BMAD-style planning can be overkill for simple projects, the answer is not "BMAD bad." The answer is "the task did not need that much planning state." If people say markdown drifts, the answer is not "spec files bad." The answer is "the source of truth was not maintained after implementation changed." If people say SDD is an approach rather than a specific repo, package, or model, they are pointing back to the same thing: choose the work contract, not the logo.
This is why I do not like tool rankings for this category. They flatten the part that actually changes the outcome. The same tool can be excellent in the right state model and painful in the wrong one.
Where Agiflow Fits
Agiflow's useful role in this article is specific: it is the external MCP-connected board in the state-boundary model.
That means Agiflow should not replace the spec. Requirements and intended behavior still belong in specs or repo docs when the team needs them versioned with the code. It should not replace git. Code history and implementation evidence still belong in commits, branches, pull requests, and artifacts. Agiflow's natural home is active work state: task owner, current status, blocker, approval, handoff, attached artifact, vault entry, and lock scope [19] [20].
The AI coding tools control surface article uses a related distinction: execution, control, and state surfaces are different decisions. Cursor, Claude Code, Copilot, Codex, and other assistants can remain the execution surface. A project board can own state. MCP is the bridge that lets the assistant read and update that state through scope [21].
That is first-party information gain Agiflow can credibly add to the SDD discussion. The assistant stays external. The board owns durable work state. Specs describe intended behavior. Git proves implementation history. The board answers what is active, blocked, approved, attached, handed off, or locked right now.
Use Agiflow or a similar board when the work is long-lived enough to justify that boundary. Skip it when one developer can keep the spec current and finish the change with a clean branch.
For the category layer behind this model, read MCP project management, which frames durable assistant-readable project context as a forming category [22]. For the implementation layer, read work units for AI coding agents.
Decision Checklist
Before choosing between spec-driven development tools, answer these questions:
- How many people or assistants will touch the same codebase before the work is done?
- What must survive after the session ends: requirements, implementation evidence, live status, approvals, artifacts, or locks?
- Who is responsible for updating the source of truth after implementation changes?
- Does the work need live workflow state, or is a maintained spec and clean commit history enough?
- Is the task long-lived enough to justify an external service?
If the answer is "one person, one short task, one repo," start with spec files or repo state. If the answer includes multiple tools, people, sessions, artifacts, approvals, or locks, the external-board model becomes more attractive.
The SDD market is not failing because it has no winner. It is exposing a harder truth: different teams need different homes for project memory.
Choose the storage model first. Then the feature table becomes useful.
Quick Reference
| Question | Best default |
|---|---|
| We need a restart-safe plan for one bounded feature. | Spec-file model. |
| We already treat commits, task files, and reviews as the audit trail. | Repo or git-state model. |
| Several people or assistants need shared live state. | External board over MCP. |
| We need approvals, artifacts, vault entries, or workflow locks. | External board over MCP. |
| The work is a short solo spike. | Avoid extra process. |
| The implementation keeps changing after planning. | Tighten the update loop for the source of truth. |
References
[1] GitHub Spec Kit official repository - github.com/github/spec-kit- captured 2026-07-05. Official source for Spec Kit positioning, Specify CLI workflow elements, project constitution,
- captured 2026-07-05. GitHub framing for Spec Kit workflow checkpoints and supported AI coding tools.
- captured 2026-07-05. Official source for OpenSpec positioning, proposals, specs, design, tasks, apply, archive, and
- captured 2026-07-05. Official source for BMAD positioning as an AI-driven agile framework with structured workflows
- captured 2026-07-05. Official source for requirements-first and design-first spec workflows and EARS-style
- captured 2026-07-05. Official source defining MCP as an open-source standard for connecting AI applications to
- captured 2026-07-05. Official source for hosts, clients, servers, resources, prompts, tools, and security and trust
- captured 2026-07-05. Anthropic announcement of MCP as an open standard for secure two-way connections between data
- captured 2026-07-05. Source for finite context and context engineering as the configuration of context that produces
- captured 2026-07-05. Official source for Taskmaster positioning as task management for AI-driven development and its
- captured 2026-07-05. Community comparison artifact. The opened view currently says it compares six SDD tools, so older
- captured 2026-07-05. Vendor-authored comparison used as a third-party claim about lifecycle and orchestration scope,
- captured 2026-07-05. Practitioner comparison used as one subjective test of planning depth, review overhead,
- captured 2026-07-05. Community discussion used for qualitative objections around waterfall feel, markdown drift, and
- captured 2026-07-05. Community discussion used for qualitative language around BMAD usefulness for complex systems and
- captured 2026-07-05. Community discussion used for qualitative language around planning structure and implementation
- captured 2026-07-05. Community discussion used for qualitative framing around multiple SDD methods proliferating.
- captured 2026-07-05. Community discussion used for qualitative pushback that SDD is an approach to organizing and
[19] Local Agiflow keyword clusters - apps/agiflow-app/docs/marketing/keyword-clusters.md -
captured 2026-07-05. First-party positioning source for Agiflow as a commercial project board connecting external AI
assistants over MCP with scoped board tools, prompt skills, shared state, artifacts, vault entries, and workflow locks.
[20] Local Agiflow post, AI coding team shared state -
apps/agiflow-app/src/content/blog/ai-coding-team-shared-state.mdx - captured 2026-07-05. First-party content source
for live work state as owner, status, blockers, approvals, artifacts, and handoffs.
[21] Local Agiflow post, AI coding tools control surface -
apps/agiflow-app/src/content/blog/ai-coding-tools-control-surface.mdx - captured 2026-07-05. First-party content
source for execution, control, and state surface distinctions and Agiflow as the external MCP-connected board surface.
[22] Local Agiflow post, MCP project management -
apps/agiflow-app/src/content/blog/mcp-project-management-tools.mdx - captured 2026-07-05. First-party content source
for MCP project management as a forming category for durable assistant-readable project context.
More to read
MCP Sampling Is Deprecated, but the Inference Bill Has No Default Owner
MCP Sampling is deprecated under SEP-2577, but direct provider APIs do not assign the bill. Use a five-field ownership record before choosing a replacement path.
10 min readHow to Keep One Project Board Across ChatGPT, Claude, Cursor, and Codex
Use MCP to connect ChatGPT, Claude, Cursor, and Codex to the same project board, then keep the board as the narrow source of truth for scope, status, evidence, and next action.
13 min readAI Coding Team Shared State: The Work-State Gap Better Models Expose
Better AI coding models expose the coordination layer your team never assigned: active task state, blockers, approvals, artifacts, and handoffs that survive Cursor, Claude Code, Codex, and closed sessions.
12 min readPut this project board inside ChatGPT
Open Agiflow in ChatGPT to plan campaigns, create tasks, and check what needs attention. Create a free Agiflow account when you are ready to keep the board for your team.